okio源码详细解析
概述
okio,是目前应用最多,最火的网络框架okhttp的底层依赖,它为okhttp提供了高效的I/O处理以及易用的API。
square官方是这样描述okio的
Okio is a library that complements java.io and java.nio to make it much easier to access, store, and process your data.
现有的okio分析文章已经很多了,不过这里还是按照以往的分析方法再分析一下。
ByteString
ByteString是一个不可变的byte序列,而与其相应的String类是一个不可变的字符(char)序列,因此在这方面,String和ByteStrings非常类似——一个处理字符串,一个处理字节串。ByteString也提供了处理二进制数据的api,比如将其转换为一个特定值,对其进行Base64或者utf-8的编码和解码。如果将一个UTF-8字符串编码为ByteString,他会缓存对该字符串的引用,以便稍后对其进行解码时,直接返回缓存的值即可。
几个主要的成员field
1 | final byte[] data; |
data是储存数据的成员,当调用需要改变数据内容的方法时,会直接返回一个新的ByteString对象。
uft8主要储存字节码uft8编码后的字符串,是懒加载的,只有在用到时(调用utf8()方法)才会被赋值。
1 | public String utf8() { |
hashCode同理
1 | public int hashCode() { |
构造函数和几个静态工厂方法(删去了一些判空代码)
1 | ByteString(byte[] data) { |
构造方法很简单,就是简单的接收一个字节数组,向data成员赋值。静态工厂方法,也都是将传入的对象通过某种方法转换为byte数组,从上面的方法可看到,nio的支持也是有的。encodeUtf8()方法接收一个utf-8编码的字符串,这里ByteString会将这个字符串缓存起来,如果需要用到这个字符串,直接返回,而不需要通过重新编码获得一个utf-8字符串,一个空间换时间的例子。如果有其他编码的字符串,则调用encodeString(),仅仅将其解码转换为字节数组,赋值给data。
再看一下ByteString中的toAsciiLowercase()方法。
1 | public ByteString toAsciiLowercase() { |
toAsciiLowercase()方法,寻找位于ASCII码’A’到’Z’间的字节,第一次找到之后clone()data,将其变为小写,并继续遍历之后的字符串,转变大写为小写。如果没有大写,直接返回这个ByteString的实例。toAsciiUppercase()逻辑与此方法相同,不再赘述。
Source && Sink
在分析Buffer之前还是要先分析一下这两个接口,为什么呢?看一下Buffer的继承结构
Source和Sink这两个接口非常简单,Source提供了向Buffer中写入数据的方法,而Sink提供了从Buffer中读取数据的方法。
1 | public interface Sink extends Closeable, Flushable { |
Sink和Source是相对应的,接下来单独看一下Sink。Sink有一个子接口BufferedSink,这个接口又增加了许多额外的功能。实现类RealBufferedSink仅仅相当于一个代理,所有的实现逻辑都在Buffer中。
Buffer
先看一下官方对Buffer的介绍:Buffer 是一个可变的字节序列,就和ArrayList一样,不需要预先调整缓冲区的大小。可以像操作一个队列一样操作Buffer,将数据写入队尾,或者从队头读取数据,并且使用者不需要管理读取的位置,可读取的长度或者序列的容量。Buffer的实现为Segment的连接列表,当将数据从一个buffer移动到另一个buffer时,只需要重新分配Segment的所有权,而不是进行数据的复制。
示例分析
这里放一下官方的示例,通过这段代码深入okio的核心类Buffer。
1 | private static final ByteString PNG_HEADER = ByteString.decodeHex("89504e470d0a1a0a"); |
decodePng()方法中,Okio.source(in)利用InputStream构建了一个Source实例,然后Okio.buffer()利用source实例生成了一个BufferedSource的实例pngSource,这个实例的实际类型为RealBufferedSource(这里就是一个典型的装饰模式)。通过RealBufferedSource.readByteString()读取ByteString。
1 | public final Buffer buffer = new Buffer(); |
readByteString()方法中,先通过require()方法调用request()方法,利用Source.read()将source中的数据读入到buffer中,然后又调用回Buffer.readByteString()。
1 | public ByteString readByteString(long byteCount) throws EOFException { |
readByteArray()中,先检查读取内容的长度是否会造成越界,然后构造一个长度为byteCount的字节数组作为缓存区,利用readFully()方法向数组内充填数据。readFully()方法就是简单的循环调用read()方法,直到将缓存区写满为止。那么这里可以看出,读取数据的主要逻辑都在read()方法中。至于为什么要循环调用,这里先留一个悬念,分析完之后的内容理解这样写的意义了。
1 | public int read(byte[] sink, int offset, int byteCount) { |
read()最开始获取到了成员变量head的引用,它的类型是Segment,Segment在概述中也被提到,他是okio用来储存数据的实现。所有关于okio数据的处理,都会和Segment有关。所以既然看到了Segment,这里就起一个分支先分析一下Segment。
Segment
Segment的代码非常少,算上注释也只有150行出头,完整过一遍代码也是很快的。
先看一下Segment主要的成员变量,注释里简单介绍了一下这些成员。
1 | /** Segment最多保存数据的大小 */ |
data是一个长度为8192的字节数组,通过pos和limit来控制有效数据的位置,pos标记着可读数据的位置,limit标记着可写的位置。limit - pos就是可读数据的长度,如果limit == pos,那就说明可读数据长度为零。
有next和prev两个指针,这一环形链表的典型成员变量,既然是一个环形列表的数据结构,那么肯定有相应数据结构的处理方法。
1 | public Segment pop() { |
这个方法是典型的环形列表删除元素操作,先判断列表是否为空,然后移动指针,并把Segment的前驱后继指针都指向null。如果列表删除当前元素后不为空,返回这个被删除元素的next,如果为空,则返回null。与pop()方法对应的push()方法是在当前的Segment段后插入新的Segment段,并调整指针,这里就不放代码了。
接下来,既然是存放数据,就需要有读写操作,对于Segment的读操作(将数据读入到data数组中),并没有提供对应的方法,不过看到data是package的访问级别,可以推测到读取操作是通过其他类的方法直接操作data数组来完成的,根据成员变量来看,具体操作就是向data中写入数据,并更新pos的值。而写操作(外界从data数组中取数据)与之类似,最后会改变limit的值。
用图举个例子:
初始时,data内没有数据,pos和limit指向0
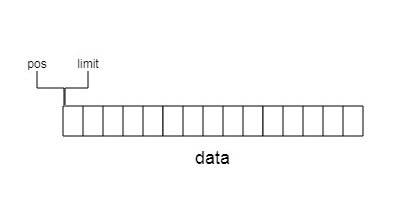
向Segment中写入6个字节数据,limit后移六位,这时可读的数据长度为limit-pos = 6
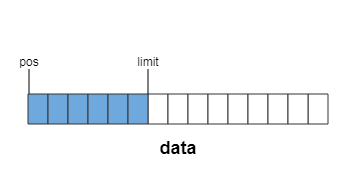
从Segment中读取5个字节数据,pos后移5位,这时仍然可读的数据长度为limit-pos = 1
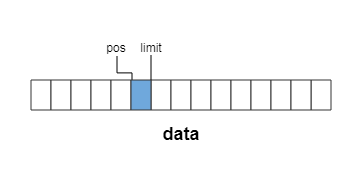
当然,每个Segment实例能存储的数据都是有限的,如果写入的数据超过了segmentA的最大大小,那么较好的做法就是将余下的数据写入segmentB中,然后将segmentB放到segmentA的后面(segmentA.next = segmentB)。这时候问题就来了,这个segmentB是否可以任意生成?显然,如果每次加入新数据都要新生成一个Segment实例,开销有点高。在okio中,是通过SegmentPool来控制Segment实例的分配和回收的,下来一起详细分析一下这个类的代码。
SegmentPool
SegmentPool更像是一个工具类,其中只有两个类方法,分别是take()和recycle(),顾名思义,这两个方法一个是获得Segment实例,一个是回收Segment实例。
先看一下take()方法:
1 | /** 下一个可用Segment实例的引用 */ |
成员变量next,就是下一个可用Segment实例的引用,如果next为空,说明SegmentPool中没有任何实例,这时会new 一个Segment,并且直接返回。如果next不会空,会返回当前的next,并让next指针重新指向被返回实例的next(这里有点绕,都叫next),将这个实例的next指针置空,最后再减掉被移出SegmentPool的字节数。调用这个方法就可以获得一个pos == limit == 0的Segment实例了。
接下来是recycle()方法:
1 | static void recycle(Segment segment) { |
recycle()接收一个被回收的Segment实例,如果这个实例next或者prev指针不为空,或者shared字段为true,则证明这个Segment无法被SegmentPool回收。若可以被回收,还需要判断一下加入这个实例后,大小会不会超出SegmentPool的最大大小,没有超过的话,把这个被回收的实例插入到整个队列的最前面,然后让成员next指向他。这里会将limit和pos置为0,对okio的处理来说,不管data里有什么数据,只要pos == limit == 0,就可以认为这个实例为空并且可以在最开头写入数据。
回到Buffer.read()
回到read()方法,这里放一下上面没有放出的完整代码
1 | public int read(byte[] sink, int offset, int byteCount) { |
结合之前的分析,可以大致猜测到,Buffer中的成员head就是存放数据的Segment链表中第一个有可读数据的Segment实例的引用。因此这里直接就是从head中取出数据,这时候就需要考虑一个情况,从前面的分析可知,每个Segment段都是有最大长度的,为8192,如果需要读取的长度大于这个数字呢?那就去链表的下一个节点去取。看一下Buffer这里是怎处理的。
获取到head的引用之后,判断当前可读数据长度(s.limit - s.pos)和需要读取的长度(btyeCount)哪个更大,如果前者更大,说明不是跨段读取,直接从当前段里读取即可;如果后者更大,那么说明当前段全部读完了,也无法达到满足要求,所以这里只能通过toCopy这个量记下已经读到的数据长度。通过System.arraycopy将内容从s.data中copy到sink中,然后调整pos指针。如果s.pos == s.limit了,说明这个段所有的数据都被读完了,调用SegmentPool.recycle()将其回收。最后通过返回toCopy,告诉方法的调用者此时读到了多少长度的字节数据。
还记得之前留下的问题吗,为什么在Buffer.readFully()中要多次调用Buffer.read()方法,是因为有可能遇到跨段数据存储的情况,如果一个segment的内容小于需要读取的内容byteCount,那将这些内容读完之后,得到已经读取到的toCopy长度,再用byteCount-toCopy,去下一个segment中读取数据,如此循环。
Buffer.write()
分析完read(byte[] sink, int offset, int byteCount)方法,顺势分析一下write(byte[] source, int offset, int byteCount)方法,以完善对Buffer操作字节数据的最基本认识。
1 | public Buffer write(byte[] source, int offset, int byteCount) { |
其实大体思路和read()是一样的,需要考虑多个数据段的情况,当读取到的数据少于byteCount时,就会持续进行写入数据的操作。和read()不同之处就是,需要考虑Segment添加的问题,这个功能由writableSegment()方法来完成。
1 | Segment writableSegment(int minimumCapacity) { |
如果head为空,说明当前buffer内还没有数据,调用SegmentPool.take()从SegmentPool中得到一个Segment对象,让head指向它,并将其前驱后继指针都指向自己,形成一个环。
如果不为空,说明head已有指向的实例。用tail指向整个环形链表的最后一个实例(环形链表中head.prev就是最末尾的实例),然后,如果需要写入的数据长度大于tail的可写长度,就向链表的末尾新增一个Segment实例,并返回它进行读写操作。为什么这里传入的参数是1?因为为了数据的连贯,就算当前的tail可写入数据的长度只有1了,也要在这次循环中为其写入一个字节,然后在下次循环中,新加入一个Segment实例。因此这个方法的作用就是分配给调用者一个可以写入指定字节数的Segment。
获得了Segment之后,就从sourcecopy数据写入Segment,并改变segment的limit。
Buffer与Buffer之间的操作
除了Buffer直接和字节数组进行交互,Buffer之间还可以进行交互,并且,Buffer之间的操作才是真正发挥Segment作用的地方。
先看一下write(Buffer source, long byteCount)方法
1 | public void write(Buffer source, long byteCount) { |
这个方法将source的数据读到当前的Buffer实例(this)。判断1:所读取的数据长度是完全在source.head内,如果在段内,判断1为true,则去获取this.tail。判断2:tail不为空,且有足够空间写入数据。判断2为true时,通过调用writeTo()方法,将数据写入当前实例的tail中,然后结束写入操作。
1 | public void writeTo(Segment sink, int byteCount) { |
如果sink.limit + byteCount > SIZE,则说明sink可供写入数据的位置不够了,如果要写入的话,必须将有效的数据向前平移一段,空出来足够的空间写入数据,具体平移多少?最好是直接将limit指向limit - pos的位置,然后将pos指向0,这样sink的有效数据段前就没有空余的位置了,很好利用了空间。如果这样,余下的空间依旧不足,则抛出IllegalArgumentException。如果足够,将数据平移之后,改动sink.limit和sink.pos。
接下来就是将当前实例的数据写入sink中了,通过System.arraycopy()写入数据,然后因为当前Segment实例的内容被读取了,pos位置要后移,sink写入了新内容,limit后移。这样就将一个Segment实例的数据写入到另一个Segment实例中了。
回到write()方法中,如果判断2为false,说明this.tail剩余的控件写不下这一段数据,因此需要一个新的Segment实例来存放这些数据。okio通过Segment.split()处理这种情况。
1 | public Segment split(int byteCount) { |
这里的判断需要读取的字节长度是否大于等于SHARE_MINIMUM。这个SHARE_MINIMUM量涉及到了对Segment分段的处理策略。Segment性能提升较高的原因,就是在某些情况下用空间换时间,并且设定了阈值,在空间和时间的消耗上做了平衡。
split()方法中,如果byteCount>=SHARE_MINIMUM为true,为了避免大数据量的copy,会通过new Segment(this)新建一个shared Segment,共享当前Segment的数据,并且shared Segment的shared字段为true,也就是说shared Segment只能被读取,不能写入数据。byteCount>=SHARE_MINIMUM为false时,为了避免Buffer的数据链中有太多不可写入的,数据占比量非常小的Segment,在需要读取的数据量很小时,就直接从SegmentPool中拿一个Segment实例,并将这些少量数据copy到新的Segment中。最后,移动segment的pos和limit限定数据的操作范围,将其放到当前实例的prev上,返回segment的引用。
再回到write()方法,source.head = source.head.split((int) byteCount)这一句调用了split,说明这一句是将原本的source.head从[pos..limit)分成了[pos..pos+byteCount)和[pos+byteCount..limit)两段,而前面一段正是需要写入this,并可以被移动的数据Segment。准备好source的数据之后,就需要通过将source的Segment直接链到this.tail上。代码中,记录了移动的Segment的数据大小,然后如果this.head为空,那么直接将source.head作为this.head,如果不为空,将source.head插入tail之后,并且调用Segment.compact()对数据进行压缩,减小空间浪费。能够被移动的数据段,只有以下几种情况
- 整个数据段都要被移动
- 通过split方法分割的数据段
介绍完了Buffer之间的数据操作,接下来看一下数据如何进行压缩。
1 | public void compact() { |
首先判断当前Segment是否可被压缩(当前Segment链表超过一个Segment、前一个Segment可以写入数据,前一个Segment的剩余空间足够写入当前Segment的所有数据)。如果可以压缩,调用writeTo()方法,将所有可用的数据写入prev中,然后将当前Segment放入SegmentPool中。
注意一下这里的剩余空间availableByteCount计算方法SIZE - prev.limit + (prev.shared ? 0 : prev.pos)。prev.shared为true时,说明prev为共享段(shared segment),prev.pos之前的数据都是无效的,可以被有效数据覆盖,因此prev.shared为treu时,prev.pos可以从0开始计算。
TimeOut
TimeOut是okio提供的新的功能,可以在流长时间未响应时结束操作。